DevOps: What It Is, How It Works, and What to Watch For


What is DevOps? DevOps is a set of practices and cultural shifts that combine software development (Dev) with IT operations (Ops) to shorten the delivery lifecycle, increase deployment frequency, and improve reliability. It replaces handoffs between siloed teams with shared ownership, automation, and continuous feedback, so the same group that writes the code also runs it in production.
Key takeaways
- DevOps is not a tool or a job title. It is a way of organizing teams around continuous delivery, shared ownership, and measurable reliability.
- The core practices are CI/CD, infrastructure as code, observability, automated testing, and incident response. Each one removes a manual step that slows releases.
- Mature DevOps teams ship multiple times per day with change-failure rates below 15%, according to the annual DORA State of DevOps report.
- Adoption fails when it is treated as a tooling project. It succeeds when leadership rewires incentives around shared service-level objectives.
- MLOps and platform engineering are direct descendants of DevOps. They apply the same delivery model to machine-learning and internal developer platforms.
What does DevOps mean?
DevOps is a portmanteau of "development" and "operations." The term was coined in 2009 by Patrick Debois at the first DevOpsDays conference in Ghent, Belgium. It emerged as a response to a chronic problem: developers were rewarded for shipping new features quickly, while operations teams were rewarded for keeping systems stable. These two goals were structurally in conflict, which produced long release cycles, change freezes, and finger-pointing during outages.
The DevOps answer is to collapse the boundary. The team that writes the service also operates it. Releases stop being big-batch events and become continuous, automated, and reversible. Culture, automation, measurement, and sharing (the so-called CAMS model) sit underneath the practice.
How DevOps works: the lifecycle
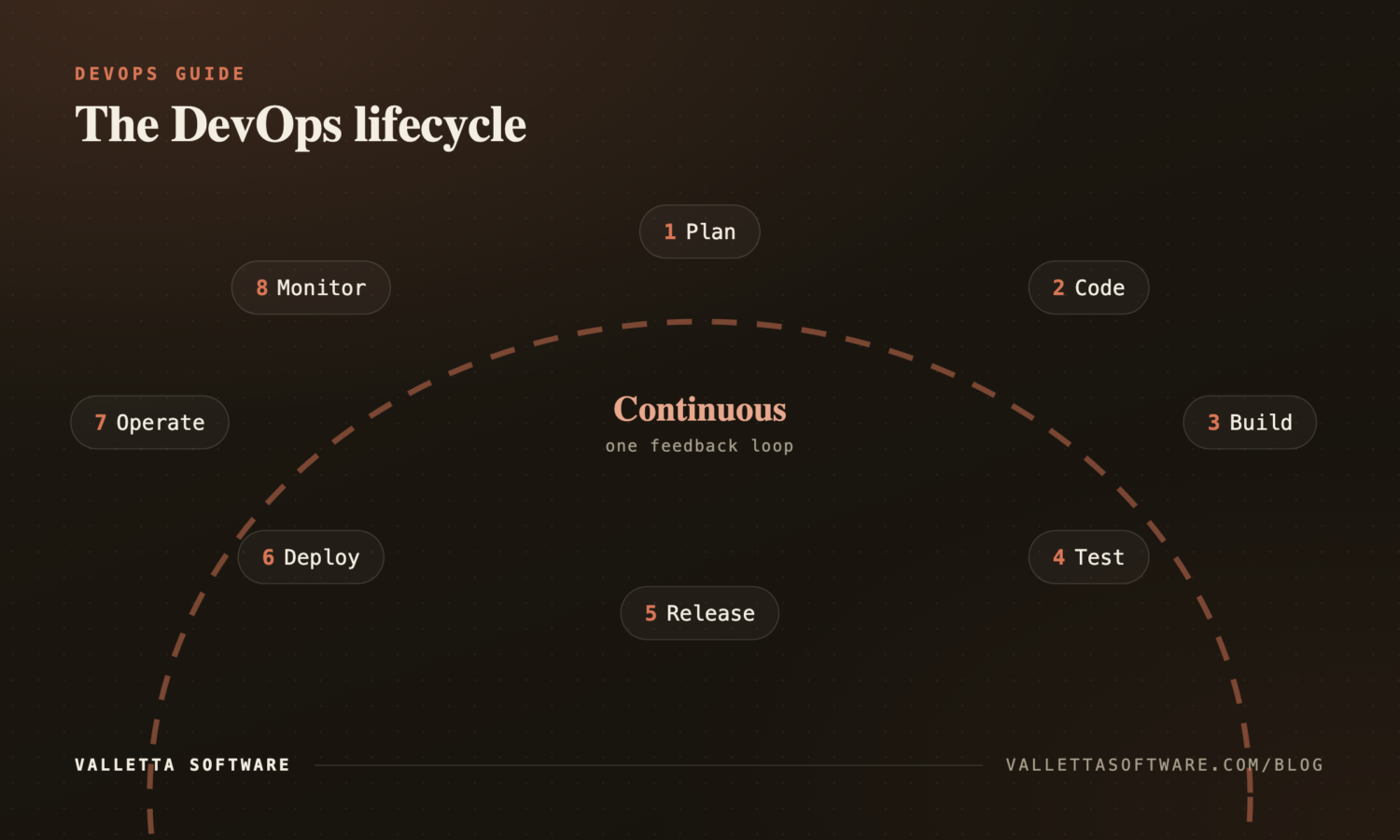
A DevOps lifecycle is a continuous loop, often drawn as an infinity symbol. Each stage feeds the next, and feedback from production loops back to planning. The eight commonly cited stages are:
- Plan: define what to build, often in small increments tracked in Jira, Linear, or GitHub Issues.
- Code: write and version code in Git, gated by pull-request reviews.
- Build: compile and package the application, typically into a container image.
- Test: run automated unit, integration, and security tests in CI.
- Release: promote the artifact through environments (staging, then production).
- Deploy: roll out to production using strategies like blue-green or canary.
- Operate: keep the service running with monitoring, on-call rotations, and runbooks.
- Monitor: collect telemetry (metrics, logs, traces) and feed insights back into planning.
This loop is implemented through a DevOps pipeline, which is the automated path a code change takes from a developer's laptop to a production server. A well-built pipeline removes manual steps, validates every change with tests, and produces an immutable artifact that can be promoted across environments without rebuilding.
Core DevOps practices
Continuous integration and continuous delivery (CI/CD)
CI is the practice of merging code changes into a shared trunk multiple times per day. Each merge triggers an automated build and test suite. CD extends this by automatically packaging and deploying every passing build to staging or production. CI catches integration bugs within minutes instead of weeks. CD turns deployment into a routine, low-risk event.
Infrastructure as code (IaC)
Servers, networks, databases, and Kubernetes clusters are defined in declarative files (Terraform, Pulumi, CloudFormation) instead of provisioned by hand. The infrastructure is then versioned, reviewed, and deployed through the same pipelines as application code. We cover this in depth in our guide to Infrastructure as Code.
Observability
Production systems generate three pillars of telemetry: metrics (counters and gauges), logs (timestamped events), and traces (request paths across services). Modern stacks like Prometheus + Grafana, Datadog, or Honeycomb give engineers the ability to ask new questions about live systems, not just see pre-built dashboards.
Automated testing and shift-left security
Tests run on every commit. Security scanning runs in the same pipeline, well before code reaches production. Static analysis, dependency scanning, container-image scanning, and secrets detection catch most vulnerabilities at the source, not after a pen test six months later.
Incident response and SRE
Site reliability engineering, introduced by Google, formalized parts of DevOps into measurable practices: service-level objectives (SLOs), error budgets, blameless postmortems, and on-call rotations with a maximum incident response time. SRE is not a separate discipline from DevOps. It is a specific implementation pattern.
What is a DevOps engineer?
A DevOps engineer is a generalist who builds and operates the systems that other developers ship code on. The role typically covers CI/CD pipelines, cloud infrastructure (AWS, Azure, GCP), container orchestration (Kubernetes), observability stacks, and security automation. In smaller companies a DevOps engineer may also run database administration, networking, and on-call. In larger orgs the role splits into platform engineering, SRE, and security engineering specializations.
The DevOps toolchain in 2026
There is no canonical DevOps tool stack, but most modern teams pick from this list:
- Source control: GitHub, GitLab, Bitbucket.
- CI/CD: GitHub Actions, GitLab CI, CircleCI, Jenkins, Buildkite.
- Container build and registry: Docker, BuildKit, Amazon ECR, GitHub Container Registry.
- Orchestration: Kubernetes (EKS, GKE, AKS) for stateful, multi-service workloads; ECS or Fly.io for smaller surface areas.
- Infrastructure as code: Terraform or OpenTofu, Pulumi, CloudFormation, Crossplane.
- Observability: Prometheus + Grafana, Datadog, New Relic, Honeycomb, OpenTelemetry.
- Secrets management: HashiCorp Vault, AWS Secrets Manager, Doppler, 1Password Secrets Automation.
- Incident response: PagerDuty, Opsgenie, Incident.io, FireHydrant.
For a deeper breakdown of when to use Kubernetes versus Docker alone, see our Kubernetes vs Docker comparison.
What about Azure DevOps?
Azure DevOps is Microsoft's branded suite of products: Azure Boards (planning), Azure Repos (Git hosting), Azure Pipelines (CI/CD), Azure Artifacts (package registry), and Azure Test Plans. It is one possible implementation of DevOps tooling, not a synonym for the practice. A team can do DevOps with no Microsoft products at all, or with Azure DevOps end to end. The cultural and process work is the same in either case.
DevOps in cloud computing
Cloud platforms (AWS, Azure, Google Cloud) are not DevOps, but they are what made modern DevOps practical. Three cloud capabilities matter most:
- On-demand provisioning: spinning up infrastructure in seconds enables ephemeral preview environments and rapid rollback.
- Managed services: managed databases, queues, and Kubernetes clusters let small teams operate workloads that would have needed a dedicated DBA and netops team a decade ago.
- Pay-per-use billing: turning unused infrastructure off costs nothing extra, which makes experimentation cheap.
The cloud also created the FinOps discipline, which applies DevOps thinking to cost: continuous monitoring of spend, blameless retros on cost spikes, and tagged budgets that engineering teams own.
DevOps and MLOps
MLOps is what you get when you apply DevOps thinking to machine-learning systems. The extra problems MLOps solves are reproducible model training, dataset versioning, model deployment, drift monitoring, and production safety for non-deterministic systems. We cover the lifecycle in detail in our MLOps guide. If your team is moving from "we have a model in a notebook" to "we serve it in production at scale," MLOps is the discipline to read up on.
How teams adopt DevOps
The hardest part of DevOps adoption is rarely the tools. It is the change in incentives, ownership, and team boundaries. Patterns that work:
- Start with one team and one service. A pilot proves the model before scaling.
- Measure with the DORA metrics: deployment frequency, lead time for changes, change-failure rate, mean time to restore. Public benchmarks exist for all four.
- Build a platform team early. The platform team's job is to make the right thing the easy thing for product teams.
- Move security left. Embed scanners in CI; do not bolt on a security review at the end.
- Reward shared ownership. If only operations is on call, developers will not write reliable code.
For practical guidance on what works in production today, read our 2026 DevOps best practices guide.
What to watch for in 2026
- AI in the pipeline: Copilot-style code review, automated incident triage, and LLM-based runbook execution are moving from demos to production.
- Platform engineering is overtaking generic DevOps as the way large orgs structure their internal tooling. See our platform engineering services overview.
- FinOps is becoming a board-level concern as cloud bills outgrow some teams' visibility.
- Supply-chain security is mandatory. SBOMs, signed builds, and provenance are no longer optional in regulated industries.
Where to go from here
If you are building out a DevOps capability and need senior engineers fast, see our DevOps consulting services. Pre-vetted teams, deployed in 48 hours, billed transparently. Schedule Free Consultation to scope it.

Frequently asked questions
Is DevOps a job or a methodology?
It is a methodology, although the title "DevOps engineer" is common. The methodology defines how teams build and run software. The job title is one of several implementations of that methodology.
What is the difference between DevOps and Agile?
Agile is about how you plan and build software in short iterations. DevOps is about how you ship and run it continuously. They are complementary: Agile delivers DevOps the small batches of work that DevOps then deploys with low risk.
Is DevOps only for large companies?
No. The smaller the team, the more DevOps matters, because there is no separate ops department to absorb the friction. Two-person startups and Fortune 500 platforms both run on DevOps principles.
What is the difference between DevOps and SRE?
SRE is one specific implementation of DevOps, originated at Google. It adds quantitative reliability targets (SLOs, error budgets) and on-call rotations as formal mechanisms. All SRE is DevOps, but not all DevOps teams adopt SRE rigorously.
How long does it take to adopt DevOps?
A single pilot team can ship a working CI/CD pipeline and IaC in 4 to 8 weeks. Cultural rollout across a 100-engineer org typically takes 12 to 18 months and requires executive sponsorship.